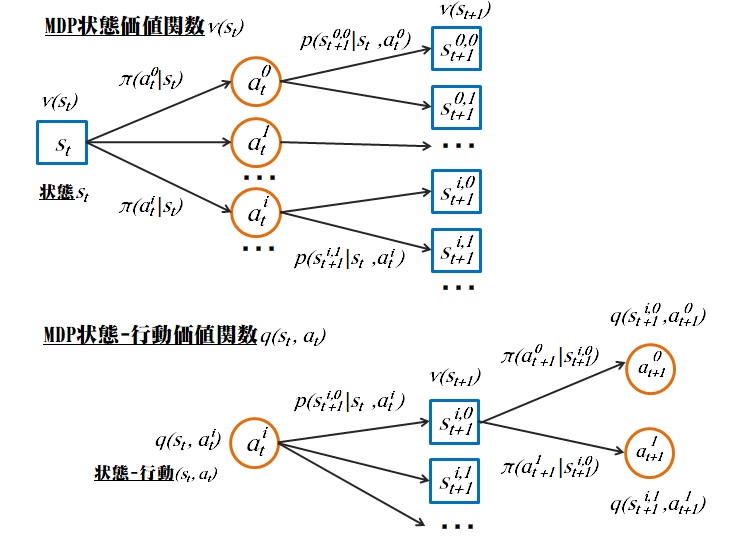
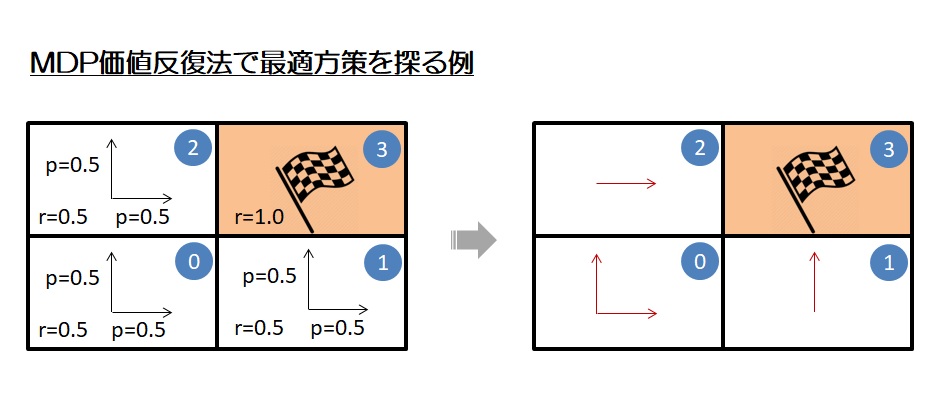
はじめに
頻出パターンをマイニングするためのアルゴリズムとして、Aprioriアルゴリズムはデータセットを複数回スキャンする必要があり、I/Oは大きなボトルネックとなる。この問題を解決するために、FP-TreeアルゴリズムまたはFP-Growthアルゴリズムとも呼ばれる手法を用いる。またFP-Treeアルゴリズムでは並列計算の手法も施して大量のデータマイニングに対応可能となる。
アルゴリズム
概要
まずは下記例のdataSetのように、Aはデータセットからカントして計8回出現したため、最初の位置に配置されるようにヘッダテーブル(Header Table)をまとめる。それからアイテムをFP-Treeにマッピングする。ヘッダテーブルにあるアイテムはFP-Treeに指して紐付けられる。最後にヘッダテーブルの下のアイテムから上への順でマイニングして、頻出アイテムセットを取得する流れになる。
miniSupport = 2
step1 dataSet:
[['A', 'B', 'C', 'E', 'F', 'O'],
['A', 'C', 'G'], ['E', 'I'],
['A', 'C', 'D', 'E', 'G'],
['A', 'C', 'E', 'G', 'L'],
['E', 'J'],
['A', 'B', 'C', 'E', 'F', 'P'],
['A', 'C', 'D'],
['A', 'C', 'E', 'G', 'M'],
['A', 'C', 'E', 'G', 'N']]
step2 sorted dataset: {frozenset({'F', 'C', 'O', 'A', 'E', 'B'}): 1, frozenset({'A', 'G', 'C'}): 1, frozenset({'E', 'I'}): 1, frozenset({'C', 'D', 'A', 'G', 'E'}): 1, frozenset({'C', 'A', 'G', 'L', 'E'}): 1, frozenset({'J', 'E'}): 1, frozenset({'F', 'C', 'P', 'A', 'E', 'B'}): 1, frozenset({'A', 'D', 'C'}): 1, frozenset({'C', 'M', 'A', 'G', 'E'}): 1, frozenset({'C', 'N', 'A', 'G', 'E'}): 1}
step3 headerTable: {'F': [2, <__main__.treeNode object at 0x7f4bcea88240>], 'C': [8, <__main__.treeNode object at 0x7f4bcea88f28>], 'A': [8, <__main__.treeNode object at 0x7f4bcea882b0>], 'E': [8, <__main__.treeNode object at 0x7f4bcea882e8>], 'B': [2, <__main__.treeNode object at 0x7f4bcea88ef0>], 'G': [5, <__main__.treeNode object at 0x7f4bcea88390>], 'D': [2, <__main__.treeNode object at 0x7f4bcea88470>]}
conditional tree for: {'B'}
ヘッダテーブルの作成
下記Header Tableのようにヘッダテーブルをまとめる。
step3 headerTable: {'A': 8, 'C': 8, 'E': 8, 'G': 5, 'B': 2, 'D': 2, 'F': 2}
FP-Treeの作成
下記FP-TreeのようにFP木をまとめる。
step3 FP-Tree:
Null Set : 1
A : 8
C : 8
E : 6
B : 2
F : 2
G : 4
D : 1
G : 1
D : 1
E : 2
FP-Treeのマイニング
ヘッダテーブルの下のアイテムから上への順でマイニングする。ヘッダテーブルのアイテムに対して、条件パターンベース(Conditional Pattern Base)をまとめて条件FP-Tree(Conditional FP-Tree)を得られる。また頻出度が少ないノードを削除する。この方法で頻出パターンをマイニングする。
step4 conditional tree for: {'B'}
Null Set : 1
A : 2
C : 2
E : 2
step4 conditional tree for: {'C', 'B'}
Null Set : 1
A : 2
step4 conditional tree for: {'E', 'B'}
Null Set : 1
A : 2
C : 2
step4 conditional tree for: {'C', 'E', 'B'}
Null Set : 1
A : 2
step4 conditional tree for: {'C'}
Null Set : 1
A : 8
step4 conditional tree for: {'D'}
Null Set : 1
A : 2
C : 2
step4 conditional tree for: {'C', 'D'}
Null Set : 1
A : 2
step4 conditional tree for: {'E'}
Null Set : 1
A : 6
C : 6
step4 conditional tree for: {'C', 'E'}
Null Set : 1
A : 6
step4 conditional tree for: {'F'}
Null Set : 1
A : 2
B : 2
C : 2
E : 2
step4 conditional tree for: {'F', 'B'}
Null Set : 1
A : 2
step4 conditional tree for: {'F', 'C'}
Null Set : 1
A : 2
B : 2
step4 conditional tree for: {'F', 'B', 'C'}
Null Set : 1
A : 2
step4 conditional tree for: {'F', 'E'}
Null Set : 1
A : 2
B : 2
C : 2
step4 conditional tree for: {'F', 'E', 'B'}
Null Set : 1
A : 2
step4 conditional tree for: {'F', 'E', 'C'}
Null Set : 1
A : 2
B : 2
step4 conditional tree for: {'F', 'E', 'B', 'C'}
Null Set : 1
A : 2
step4 conditional tree for: {'G'}
Null Set : 1
A : 5
C : 5
E : 4
step4 conditional tree for: {'C', 'G'}
Null Set : 1
A : 5
step4 conditional tree for: {'G', 'E'}
Null Set : 1
A : 4
C : 4
step4 conditional tree for: {'C', 'G', 'E'}
Null Set : 1
A : 4
step4&5 frequentItemList: [{'A'}, {'B'}, {'A', 'B'}, {'C', 'B'}, {'C', 'B', 'A'}, {'E', 'B'}, {'A', 'E', 'B'}, {'C', 'E', 'B'}, {'C', 'E', 'B', 'A'}, {'C'}, {'C', 'A'}, {'D'}, {'A', 'D'}, {'C', 'D'}, {'C', 'A', 'D'}, {'E'}, {'A', 'E'}, {'C', 'E'}, {'C', 'E', 'A'}, {'F'}, {'F', 'A'}, {'F', 'B'}, {'F', 'B', 'A'}, {'F', 'C'}, {'F', 'A', 'C'}, {'F', 'B', 'C'}, {'F', 'B', 'A', 'C'}, {'F', 'E'}, {'F', 'E', 'A'}, {'F', 'E', 'B'}, {'F', 'E', 'B', 'A'}, {'F', 'E', 'C'}, {'F', 'E', 'A', 'C'}, {'F', 'E', 'B', 'C'}, {'F', 'C', 'A', 'E', 'B'}, {'G'}, {'A', 'G'}, {'C', 'G'}, {'C', 'G', 'A'}, {'G', 'E'}, {'A', 'G', 'E'}, {'C', 'G', 'E'}, {'C', 'G', 'E', 'A'}]
手順のまとめ
1・データセット(Data Set)をスキャンして、すべての1アイテムのカウントを取得する。次に、サポート度がしきい値(miniSupport例えば=2)より低いアイテム(非頻出アイテム)を削除して、ヘッダーテーブル(Header Table)に1アイテムを入れて、サポート度の降順(Sort 大→小)に並べる。
2・データセットを再度スキャンして、サブセット(トランザクションセット)毎に非頻出アイテムを除外して、サポートの降順(大→小)に並べて用意しておく。
3・上記用意したサブセットを読み取って、FP-Treeに挿入する。ソートされた順序で最初ソートされたノードは親ノード(Parent Node)で、あとにソートされたノードは子ノード(Child Node)にする。共通の親ノードが存在する場合、対応する共通の親ノードのカウントは1つ増やす。挿入後、新しいノードが生成される場合、ヘッダーテーブルに対応するノードは、ノードリスト(Node List)を介して新しいノードにリンク(Node Link)される。すべてのデータがFPツリーに挿入されるまで、FP-Treeを作成する。
4・ヘッダーテーブルの一番下のアイテムから上へ条件付きパターンベース(Conditional Pattern Base)を見つける。条件付きパターンベースからの再帰マイニングによって、ヘッダーテーブルアイテムの頻出アイテムセット(Frequent Item Set)を取得する。
5・頻出アイテムセット内のアイテム数が制限されていない場合、ステップ4を繰り返して、すべての頻出アイテムセットを取得する。それ以外の場合、アイテム数の要件を満たす頻出アイテムセットのみを取得する。
ソースコード
以下Peter氏が作成したソースコードをご参照ください。
https://github.com/pbharrin/machinelearninginaction3x/tree/master/Ch12
参考文献
[1] PeterHarrington. Machine Learning in Action.
ロボット・ドローン部品お探しなら