はじめに wiki: 「カルマンフィルタ\((Kalman Filter, KF\)と略す\()\) は、誤差のある観測値を用いて、ある動的システムの状態を推定あるいは制御するための、無限インパルス応答フィルタの一種である」。観測値 に観測雑音、状態予測値 にシステム雑音があって場合により時間とともに誤差がドンドン蓄積してそのまま使えないので、観測と予測のガウス性を利用した線形センサデータフュージョンがカルマンフィルタの原点である。
キーワード 状態空間モデル、線形システム、ガウス分布、最小二乗法、最小解析誤差(共分散行列)、予測値、観測値、推定値、カルマンゲイン、線形化、拡張カルマンフィルタ
状態空間モデル 時系列解析 の中で、予測値と観測値の間何らかの因果関係を見つけて、何らかの方法でそれらのデータを絡んでモデル化して状態を推定していく。ここで汎用的な状態方程式 、観測方程式 は以下の式にする。
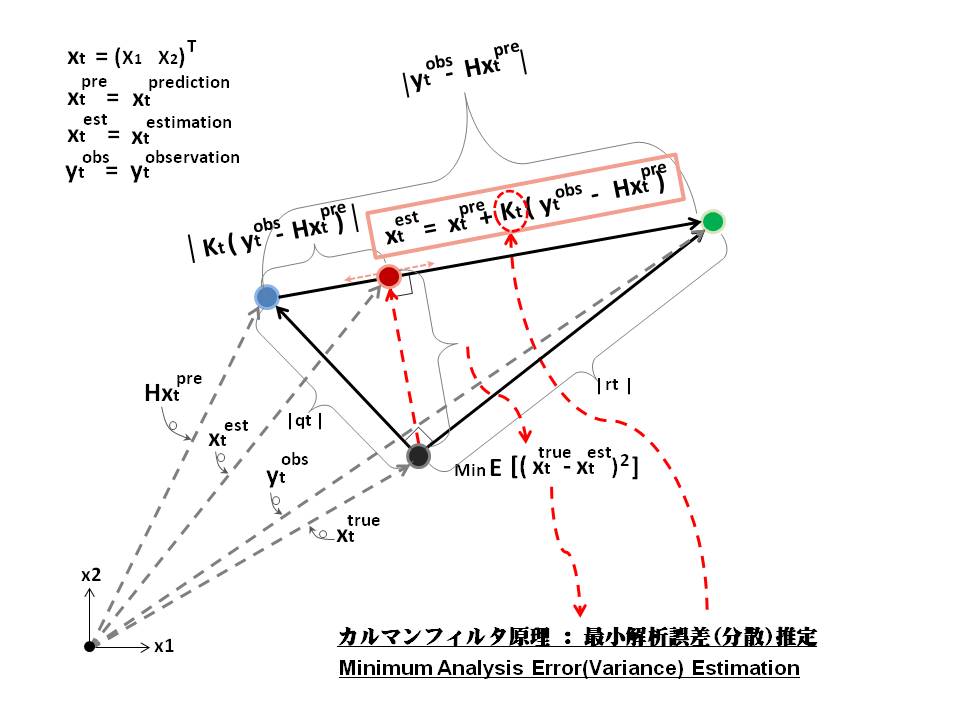
基本原理 カルマンフィルタの原理は以下のイメージに示すように、最小解析誤差推定 (最小二乗)から予測値、観測値をそれぞれの割合\(I-K_t H_t , K_t\)で線形合成した値を状態推定値 にする。kalman_filter_principle_n
式の導出 ベイズ定理やガウス分布からいくつかの導出方法はあるが、本記事は最もシンプルな最小二乗法を用いて、カルマンフィルタの黄金\(5\)式を誘導してみよう。
線形システム \(F(⋅)、H(⋅)\)とも線形関数の場合、以下線形カルマンフィルタの誘導となる。例えば\( F(x)=Ax+B\)、\(A、B\)とも実数行列、\(x\)は変数行列とする。
まずは、予測値(数学期待)を求めるのは出発点なので、すべては以下の式(再掲)から始まる。
解析誤差(共分散行列)は以下の式より求める。
ここから二乗の最小化より解析誤差(共分散\(P_t\))を最小値に至る\(K_t\)を求める。
これで、状態予測時、式\(\star\)及び式\(\star\star\)から得られる\({\small P_t = F_{t-1}P_{t-1}F_{t-1}^T + Q_{t-1} \space ** }\)を上式に代入して、\( K_t\)は以下のように簡略化される。
非線形システム 前述線形カルマンフィルタの\(F(⋅),H(⋅)\)は非線形関数になった場合、\(f(⋅),h(⋅)\)と記す。ティラー展開の最初の\(2\)項のみを使って、如何なる非線形関数とも線形化されるが、\(3\)項目以降は切り捨てられるので誤差を招くことにもなる。例えば、\(f(x)=Ax^2+B\)、\(A,B\)とも実数行列、\(x\)は変数行列として、ティラー展開の最初の\(2\)項のみを使って、即ち\( f(a)+\frac {\partial {f(x)}} {\partial {x}}|_{x=a}(x-a) \) のように\(f(x)\)を、\(Aa^2+B+2Aa(x-a)\)に線形化される。状態予測の際、線形カルマンフィルタの\(F\)を\(f\)、観測値の取り入れる際、線形カルマンフィルタの\(H\)を\(h\)に、共分散行列の計算の際、\(F,H\)を\( \frac {\partial {f(x)}} {\partial {x}}|_{x=x_{t-1}}, \frac {\partial {h(x)}} {\partial {x}}|_{x=x_t}\)に置き換えて済む。
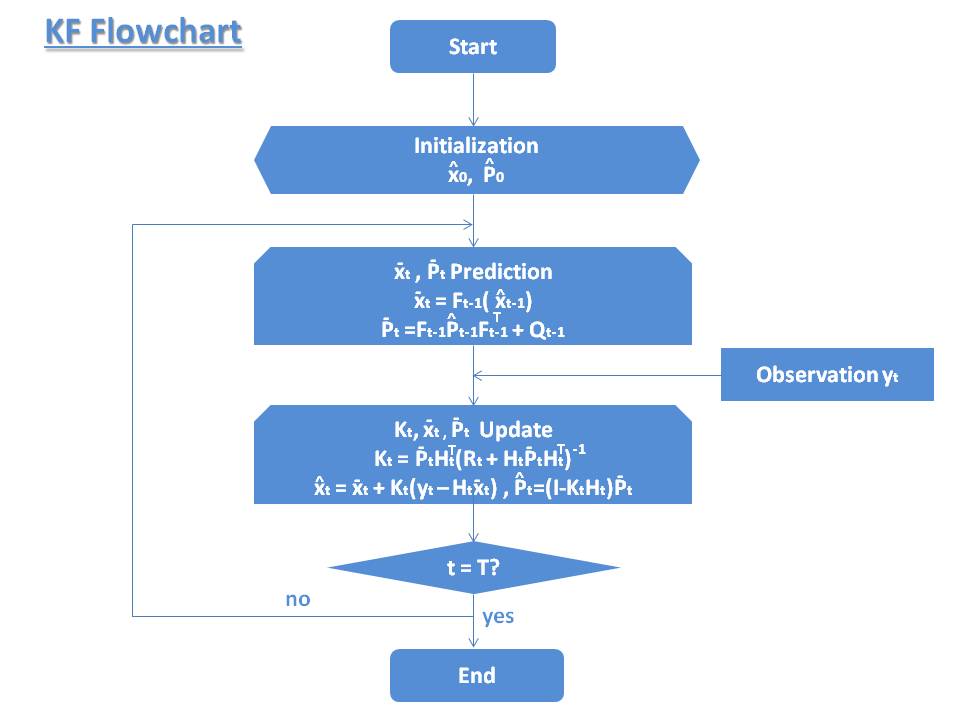
これまでカルマンフィルタの誘導で、逐次状態値推定の手順を以下のとおり整理しておく。
逐次状態推定の手順 時系列の状態推定に応用して、以下状態予測\(Predict\)→測定更新 \(Measurement \space Update\)→状態更新\(Correct, Update\)→時間更新\(Time \space Update\)→次の状態予測\(Predict\)→\(…\)の繰り返すことによって、時系列とともに状態の数学期待 と最小解析誤差(共分散) を求める手順となる。
Step0=パラメータ初期化(t=0) 状態推定(数学期待)、解析誤差共分散の初期化
Step1=状態値、共分散行列予測(t>0) $$\begin{eqnarray*}&& x_t = F_{t-1}(\hat{x}_{t-1})\\&& P_t = F_{t-1}\hat{P}_{t-1}F_{t-1}^T + Q_{t-1}\end{eqnarray*}$$
Step2=カルマンゲイン、状態値、共分散行列更新 $$\begin{eqnarray*}&& K_t = P_t H_t^T (H_t P_t H_t^T + R_t)^{-1}\\
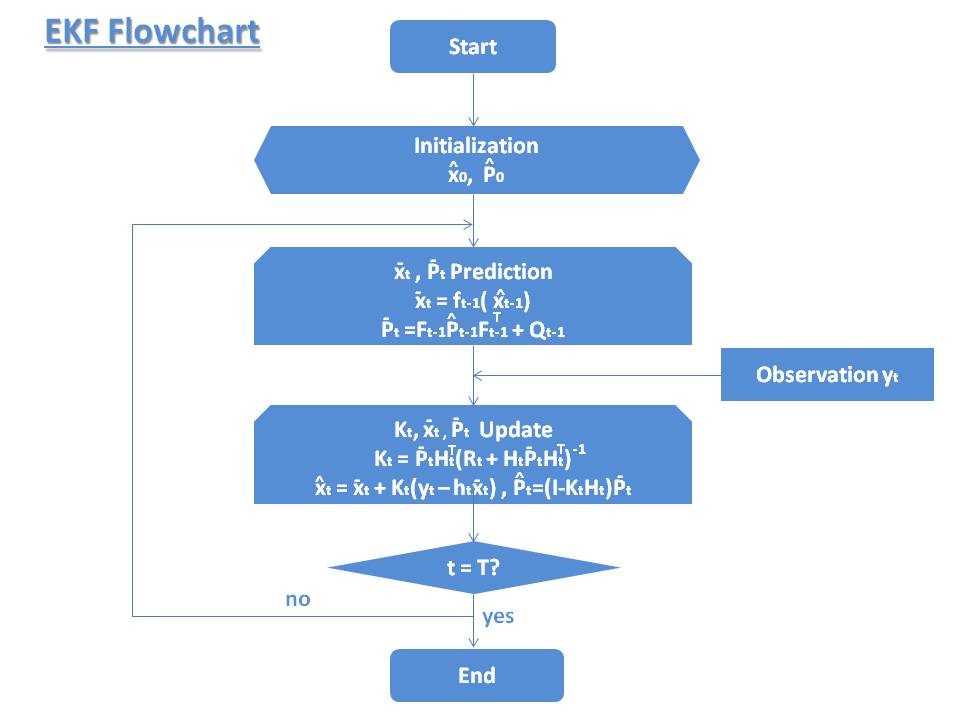
KFフローチャート Kalman_Filter_Flowchart_2 拡張カルマンフィルタ 拡張カルマンフィルタ \((Extended Kalman Filter, EKF\)と略す\()\)は、非線形フィルタリングである。前述した状態方程式、観測方程式より、以下の状態空間モデルの\(f(⋅)\)または\(h(⋅)\)が非線形関数であり、拡張カルマンフィルタが適用される。テイラー展開より、2次微分以降の項目を省略して、非線形である\(f(⋅), h(⋅)\)の1次微分を線形化とし、前述したカルマンフィルタのアルゴリズムが適用可能となる。しかし、\(f(⋅), h(⋅)\)の微分では\(f(⋅), h(⋅)\)の一部しか表現できず、この線形化処理(1次微分)が誤差を招くことになる。
状態空間モデル $$\begin{eqnarray*}&& x_t = f_{t-1}(x_{t-1}) + q_{t-1}\\&& y_t = h_t(x_t) + r_t\end{eqnarray*}$$
Step0=パラメータ初期化(t=0) $$\begin{eqnarray*}&& \hat{x}_0 = E[x_0]\\&& \hat{P}_0 = E[(x_0-\hat{x_0})(x_0-\hat{x_0})^T]\end{eqnarray*}$$
Step1=状態値、共分散行列予測(t>0) $$\begin{eqnarray*} && x_t = f_{t-1}(\hat{x}_{t-1})\\&& P_t = F_{t-1}\hat{P}_{t-1}F_{t-1}^T + Q_{t-1}\end{eqnarray*}$$
Step2=カルマンゲイン、状態値、共分散行列更新 $$\begin{eqnarray*}&& K_t = P_t H_t^T(H_t P_t H_t^T + R_t)^{-1}\\
EKFフローチャート Extended_Kalman_Filter_Flowchart_2 拡張カルマンフィルタを6軸IMUへの適用 6軸IMUへの適用例として、本サイトの記事 6軸IMU~拡張カルマンフィルタ に載ってある。
カルマンフィルタの再考 カルマンフィルタでは、状態推定値を予測結果\(x_t\)(実装例ではジャイロセンサーデータ)と観測データ\(y_t\)(実装例では加速度センサデータ)の線形結合でデータ同化とし,その解析誤差(共分散)を最小にする推定法 だと分かる。これは、状態方程式、観測方程式とも線形関数(非線形関数の場合、線形化する)、システム誤差、観測誤差の数学期待が\(0\)の正規分布との前提条件から由来した推定法である。しかし、カルマンフィルタをかけることで、状態推定値は予測結果と観測データの間にあるのは、真値からかなり乖離してしまう場合にあるのか。これはシステム誤差と観測誤差が無相関かつ直交という前提から、勿論推定値が真値と観測値の間にある、実環境の真値は分からないので推定値は真値と見なす結論に至る考えである。パーフォーマンスの検証は、比較的精確な実験環境(比較用の高精度ジャイロセンサ、加速度センサ、エンコーダ、モータ)がないと、実は容易ではない。というよりも、シミュレーションをかけてカルマンフィルタのアルゴリズムを検証するのが、確実に可能である。
参考文献 1-wikipedia: カルマンフィルタ 、オイラー角 An Introduction to the Kalman Filter マルチボディダイナミクスの基礎―3次元運動方程式の立て方
関連記事 オイラー角~ジンバルロック~クォータニオン SLAM~拡張カルマンフィルタ SLAM~Unscentedカルマンフィルタ 9軸IMUセンサ 6軸/9軸フュージョン 低遅延 USB出力 補正済み ROS対応 9軸IMU ICM-20948をロボットに組み込もう YDLIDAR G4=16m 薄型 ROS対応SLAM LIDAR 研究開発用 台車型ロボット キット
ロボット・ドローン部品