はじめに
本文には、大文字表現=行列/マトリクス、\(\boldsymbol{bold}\)小文字表現=ベクトル\(R^d\)、普通小文字表現=スカラー\(R\) と記す。
非階層クラスター分析とは異なる性質のものが混ざり合った集団から、互いに似た性質を持つものを集めてクラスターを作る方法である。ただし、予めいくつのクラスターに分けるかは先に決める必要がある。k平均法(k-means)は非階層クラスター分析の一つで、クラスターの平均(Means)を用いて、あらかじめ決められたクラスター数k個に分類する方法である。
k-means
1、全てのサンプルに最も近いクラスタセンタを探る→2、クラスタ平均値(Mean)でクラスタセンタを更新する→再度1を実行する→再度2を実行する、クラスタセンタが変わらないまで1の実行を繰り返す。
実装
複数のポイントを4クラスタに配属する。
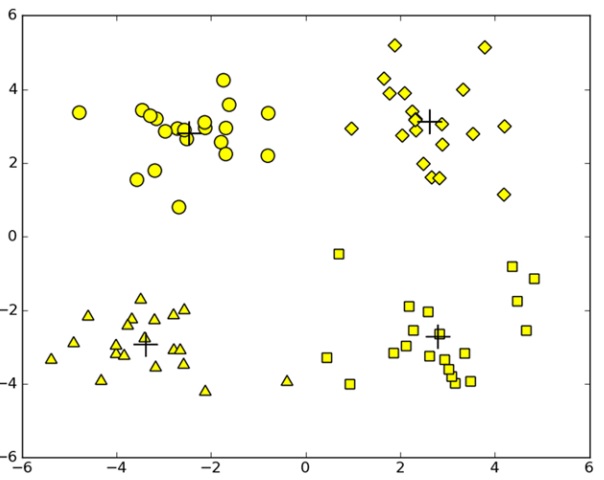
ソースコード
https://github.com/soarbear/Machine_Learning/tree/master/k_means
実行
centroids: [[-2.46149268 -0.60273756] [-0.57051504 -3.25574076] [ 2.85356363 0.16031334] [-3.54201389 -3.13476225]] centroids: [[-2.46650438 2.55882843] [ 2.12143555 -3.58637036] [ 2.8287018 1.4343227 ] [-3.59385056 -2.94282822]] centroids: [[-2.46154315 2.78737555] [ 2.54173689 -3.11892933] [ 2.71502526 2.5965363 ] [-3.53973889 -2.89384326]] centroids: [[-2.46154315 2.78737555] [ 2.65077367 -2.79019029] [ 2.6265299 3.10868015] [-3.53973889 -2.89384326]]
参考文献
[1] PeterHarrington. Machine Learning in Action.
ロボット・ドローン部品お探しなら![]()