概要
本文には、大文字表現=行列/マトリクス、\(\boldsymbol{Bold}\)小文字表現=ベクトル\(R^d\)、普通小文字表現=スカラー\(R\) と記す。
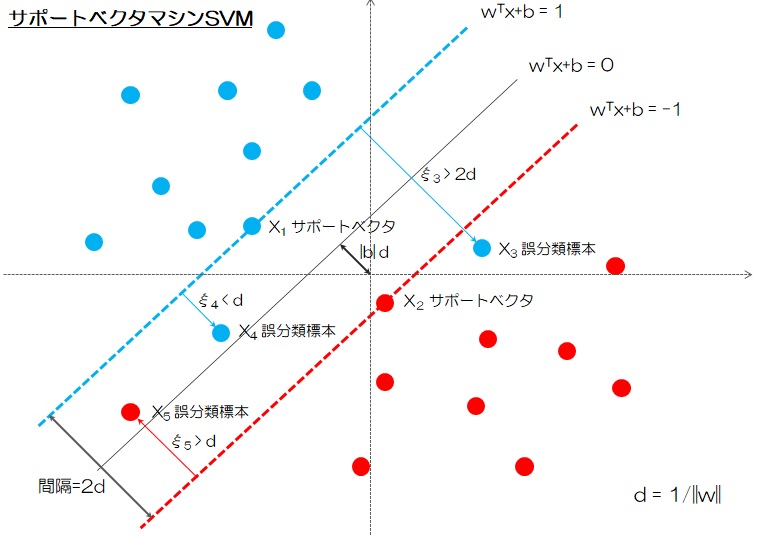
複数の標本(Sample)が分類可能と仮定する場合、直線で異なるラベルに属する標本を分類して、線形SVMが適用される。しかし、このような直線が存在しない場合、カーネルトリック(Kernel Trick)を使用して、写像された高次元空間で標本分類用の超平面(Hyper Plain)が見つかり、非線形SVMが適用される。ロジスティック回帰とは違って、境界(Border)に最も近い標本(Support Vector)の間隔(Margin)を最大化するから、標本が境界にあることが拘束条件(s.t.)である。ラグランジュ乗数法(Lagrange’s method)を利用して拘束条件つきの最適問題を拘束なし問題に簡略化して解くことになる。これで機械学習が一気に難易度を増すことになる。
線形SVM基本形
$$ \underset{w,b}{\operatorname{min}} \frac{1}{2}\boldsymbol{w}^T\boldsymbol{w}\\
s.t. \space \space y_i(\boldsymbol{w}^T \boldsymbol{x_i}+b) \ge 1, \space i=1,2,…,n $$
基本(Primal)形を解くのが難しいから、双対(Dual)形で解くようになる。
線形SVM双対形
$$ \underset{\alpha}{\operatorname{min}} \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_i \alpha_j y_i y_j \boldsymbol{x}_i^T \boldsymbol{x}_j -\sum_{i=1}^{n} \alpha_i \\
s.t. \space \space \sum_{i=1}^{n} \alpha_i y_i =0 , \alpha_i \ge 0, i=1,2,…,n $$
線形SVM双対形でも分類できない場合、標本\(\boldsymbol{x}\) を \(\phi(\boldsymbol{x})\)で高次元空間\(R^{\bar{d}}\)に写像する。
非線形SVM基本形
線形SVM基本形から、\(\boldsymbol{x}\)を\( \phi(\boldsymbol{x}) \)に置き換えて以下の式になる。
$$ \underset{w,b}{\operatorname{min}} \frac{1}{2}\boldsymbol{w}^T\boldsymbol{w}\\
s.t. \space \space y_i(\boldsymbol{w}^T \phi (\boldsymbol{x_i})+b) \ge 1, \space i=1,2,…,n $$
カーネル関数は写像(Mapping)された高次元空間における内積(Inner Product)\(\small k(\boldsymbol{x}_i,\boldsymbol{x}_j)= \phi(\boldsymbol{x}_i)^T \phi(\boldsymbol{x}_j) \)、基本形を解くのが難しいから、双対形で解くようになる。
非線形SVM双対形
非線形SVM基本形から、\(\boldsymbol{x}\)を\( \phi(\boldsymbol{x}) \)に置き換えて以下の式になる。
$$ \underset{\alpha}{\operatorname{min}} \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_i \alpha_j y_i y_j \phi(\boldsymbol{x}_i)^T \phi(\boldsymbol{x}_j) -\sum_{i=1}^{n} \alpha_i \\
s.t. \space \space \sum_{i=1}^{n} \alpha_i y_i =0 , \alpha_i \ge 0, i=1,2,…,n $$
ソフト間隔SVM基本形
理論的にはカーネル関数見つけることができるが、現実においては適切なカーネル関数を見つけることは困難な場合あり、なおかつ標本にはノイズが含まれるから、いかに誤分類なしカーネル関数を求めるなら、オーバーフィッティングに陥てしまう。ここで少量の標本に対して誤分類(Miss-Classification)を許す。
$$ \underset{w,b,\xi}{\operatorname{min}} \frac{1}{2}\boldsymbol{w}^T\boldsymbol{w}+C\sum_{i=1}^{n}\xi_i \\
s.t. \space \space y_i(\boldsymbol{w}^T \phi (\boldsymbol{x_i})+b) \ge 1-\xi_i, \space i=1,2,…,n, \\ \xi_i \ge 0, \space i=1,2,…,n $$
間隔を最適化しながら誤分類が許すが、このような誤分類の標本数がなるべく少なくする必要がある。ここでCが間隔と誤分類の標本数のバランスを取る正則化パラメータで、誤分類をどれだけ許すかを決める。Cが大きくすると誤分類の標本数が少なくなり、Cが小さくすると誤分類の標本数が多くなる傾向がある。\(\xi_i\)はスラック変数(Slackness Variable)と言って、誤分類の度合がどれだけあるのか(どれだけ緩めるか)を表すパラメータである。
ソフト間隔SVM双対形
$$ \underset{\alpha}{\operatorname{min}} \frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_i \alpha_j y_i y_j \phi(\boldsymbol{x}_i)^T \phi(\boldsymbol{x}_j) -\sum_{i=1}^{n} \alpha_i \\
s.t. \space \space \sum_{i=1}^{n} \alpha_i y_i =0 , 0 \le \alpha_i \le C, i=1,2,…,n $$
ヒンジ損失
前述のスラック変数\(\xi\)に関連してヒンジ損失(Hinge Loss)は以下の式で表す。
$$ l(s) = max(0, 1-s) $$ただし、\(s=y_i(\boldsymbol{w}^T \phi (\boldsymbol{x}))\)は標本が正しく分類されるかの信頼度である。標本が正しく分類される場合、ヒンジ損失=0、標本が誤分類される場合、つまり\(s<0\)の場合、ヒンジ損失は大きくなる。まさにヒンジ開閉のように思わせる。
実装の例
pythonのscikit-learnの機能はsklearnというライブラリに組み込まれる。sklearnにsvmというライブラリが内蔵されているので、非常に便利に利用できる。今回は非線形SVMカーネル関数のガウシアンRBF(Gaussian Radial Basis Function)を利用して標本グループを分類してみよう。
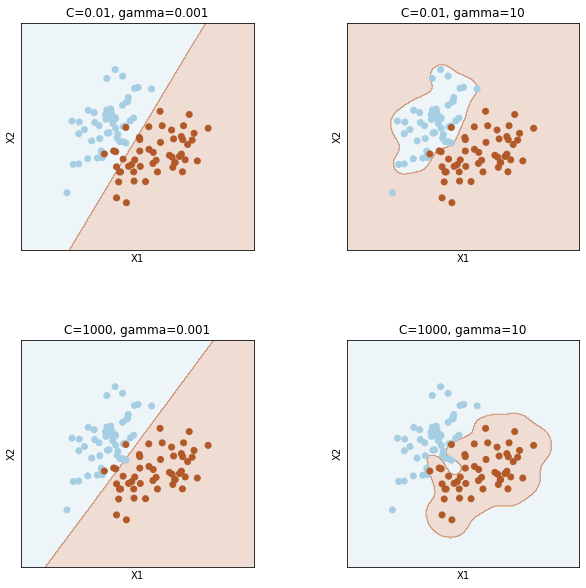
\(k(\boldsymbol{x}_i,\boldsymbol{x}_j)= exp(- \gamma (x_i-x_j)^2)\)より、\(\gamma\)はガウシアン曲面の幅を制御する調整用のパラメーターという。特徴量1のガウス分布曲線を思い出すとイメージが分かる。
ソースコードhttps://github.com/soarbear/Machine_Learning/tree/master/svm
結論
サポートベクターマシンSVMのパラメーター\((w,b)\)は、サポートベクターのみに決定されて、他の標本には関係なし。最大間隔により標本数が少なくとも分類の正確さが高い、汎化能力(Generalization Capability)が優れる、非線形問題が解決できるカーネル関数の導入とのメリットをもつ反面、標本数が大きい場合、カーネル関数の内積の計算とラグランジュ乗数の計算に標本数が関連して多大な計算量につながる。標本数は特徴量次元数より遥かに大きい\(n>>d\)場合、深層学習のほうがSVMより優れる。また適切なカーネル関数を選択するのと、ハイパーパラメータを決めるのも難しい。以上の検討結果を開発に取り組んでいきたい。
参考文献
[1] B. E. Boser, I. M. Guyon, and V. N. Vapnik. A training algorithm for optimal margin classifi ers. In Proceedings of the Annual Workshop on Computational Learning Theory, pages 144–152, 1992.5
[2] S. Boyd and L. Vandenberghe. Convex optimization. Cambridge university press, 2004.4
[3] C.-C. Chang and C.-J. Lin. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2(3):27, 2011.10
[4] Zhanghao. Derive support vector machine (SVM) from zero. 2018.10
ロボット・ドローン部品お探しなら![]()