はじめに
Google がTensorflowのResearch Modelとしてstruct2depth、vid2depthを公開したので、struct2depthを利用して単眼カメラMonocular Cameraで撮った写真から深度Depthを推定してみよう。struct2depth、vid2depthは、KITTIまたは、CITYSCAPEの学習データを通してVisual Odometry、Depthの推定を習得するモデルである。また他の学習データを入れ替えてもあり得ると考えられる。SFM:Structure From Motionに基づく技術で、Depth深度まで推定できれば、3D Recontruction3次元復元まで使われる。
実測
雑居ビール内、ドラッグストア前および、ホールで写真を撮って完了とした。
推定
画像サイズを416×128に縮小して、推定の時間を短縮する。
環境
・ Google Colab, 18.04.3 LTS Bionic Beaver, GPU Tesla k80
・ Tensorflow 1.15.2
・ Research model struct2depth/KITTI
手順
学習せずKITTIモデルをそのまま利用したので、推定手順は以下のとおり。
・tensorflow_versionを1.xに合わせる。
・ランタイムを再起動。
%tensorflow_version 1.x import tensorflow print(tensorflow.__version__)
・以下確認できるまで、またランタイムを再起動する。
TensorFlow 1.x selected. 1.15.2
・インファレンス
!python inference.py --logtostderr --file_extension png --depth --egomotion true --input_dir image --output_dir output --model_ckpt model/KITTI/model-199160
結果
単眼カメラで撮ったRGB写真、レンダリングした深度推定イメージを結果として出力される。点群データの3Dイメージは別途プログラムを作成してレンダリングRenderingとする。
うまくいく例
完璧ではないが、扉、旗まで殆ど良く推定できている。

mayaviで点群Point Cloudデータの3D表現
Mayaviは、matplotlibよりパワーアップして、強力なエンジンVTKを利用した3Dツールである。
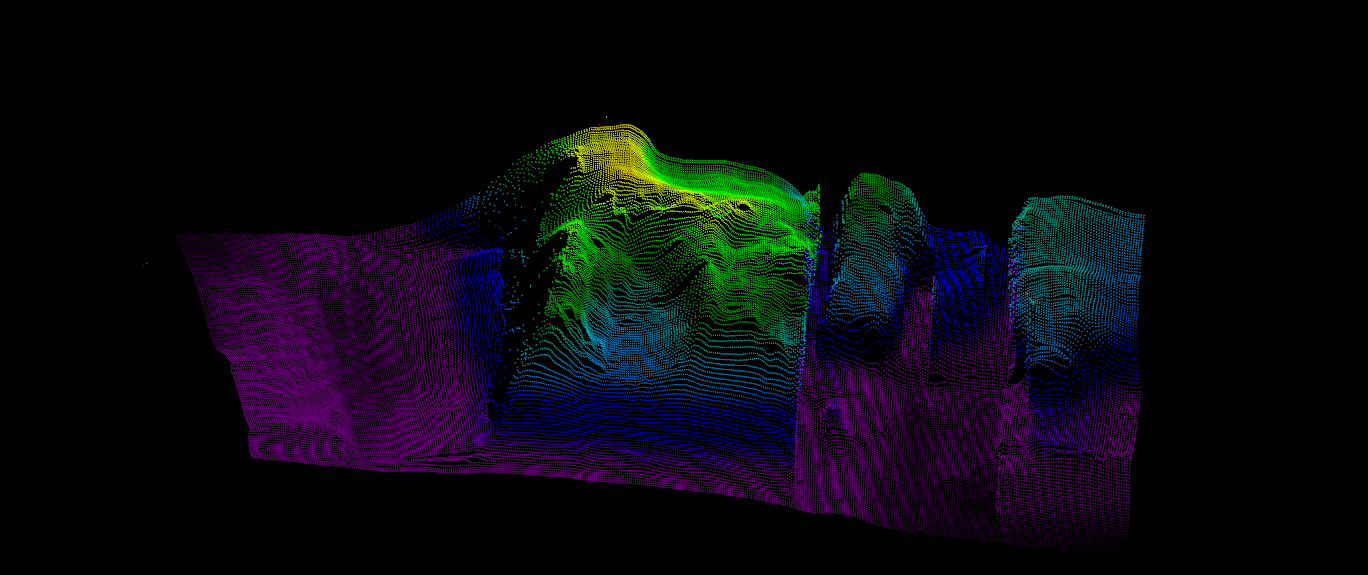
上図のように3Dで写真を細かく表現できた。点群データ(npyファイル)による3D表現のpythonソースは、Githubへ公開済み。
うまくいかない例
左下に推定が失敗と見られる。他の場所はなんとなく推定てきている。

原因を探る
・ KITTIモデルは屋外モデルでそのままでは屋内に向かない場合ある。測定環境にふさわしい学習データセット(モデル)が必要である。
・ 照明の強弱、特徴量に大きく関わること。
・ ついてはまだ実験が不十分だが、商用可能なVisual SLAMに道が長く感じさせられる。
参考文献
・Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos, Auther: Vincent Casser etc
・github google tensorflow model struct2depth
以上
ロボット・ドローン部品お探しなら![]()